
An excerpt from this article was also published in The Global Times.
"Editing 100,000 people," "producing over 500,000 notes daily," and "seven-day teaching documents." The business model represented by the "Zhengzhou Gang" on social platform Xiaohongshu utilizes massive, bulk, and replicable content publication across numerous accounts to acquire free traffic and complete a commercial closed loop. This type of operation is ubiquitous on the internet, sparking increasing reflection on "information pollution" and internet governance. The resulting "bad money drives out good" vicious cycle is even more alarming when such Chinese-language corpus "floods" the internet and becomes training content for AI large language models.
Large Language Models (LLMs) are penetrating all aspects of social life at an unprecedented speed, rapidly evolving into critical information infrastructure. However, a fundamental yet easily overlooked strategic risk is emerging: the training corpus that serves as the intelligent "foundation" for large models is facing systematic "information pollution."
This pollution is far from a simple matter of information authenticity; it is a form of meticulously planned "Cognitive Poisoning," which not only threatens the healthy development of AI technology itself but is also directly related to our cognitive security and even digital sovereignty. This is far more harmful than simply replicating a massive amount of commercial promotions on a platform.
To understand the deep-seated logic and transmission path of this "poisoning," we must establish a full-chain analysis framework. The author believes that any user-facing AI application's information input must go through four stages, and each stage is at risk of being contaminated.
Pre-training Data: This is the "native soil" where the model's worldview is formed.
Post-training Data: This is the "shaping tool" for the model's values and behavioral patterns.
Real-time Knowledge Augmentation: This is the "external water source" for the model to acquire instant information.
Application Layer Orchestration: This is the "last line of defense" before information is outputted.
This article will analyze, one by one, the specific manifestations of "Cognitive Poisoning" within these four stages, its attack methods, and their profound impact. It will also explore how we should defend our digital and cognitive sovereignty in this silent battle of offense and defense.
I. Pre-training Data: "Heavy Metal Pollution" in the Digital Age
The "intelligence" of a large model is rooted in its pre-training data. Currently, every major global large model relies on massive web datasets, such as Common Crawl. For example, Common Crawl's corpus accounts for up to 60% of GPT-3's training data. This is analogous to agriculture, where the quality of the model fundamentally depends on the quality of the "soil" in which it grows. If this "digital soil" is systemically contaminated with "heavy metal pollution," then any "digital crop" (large model) grown from it will inevitably carry an innate "toxicity".
This "soil pollution" is primarily manifested in three areas.
The first is cultural bias resulting from linguistic hegemony. The vast majority of the Common Crawl corpus is in English, which means that the model, in its initial stage of "learning the world," puts on "rose-tinted glasses" centered around English culture.
The second is the "weighted feeding" of specific knowledge sources. Taking GPT-3's training recipe as an example, a subtle operation reveals that the corpus from Wikipedia, while only accounting for 0.6% of the total volume, is given a training weight of up to 3%. This means the model is forced to "over-learn" content from Wikipedia. The consequences of this "weighting" operation are self-evident, as Wikipedia is a well-known knowledge base with a distinct "pro-Western" ideological stance on many issues. This is not a simple technical choice but a systematic, purposefully ideological weighting with the goal of pre-setting a pro-Western value framework within the model's underlying cognition.
Finally, there is the indiscriminate absorption of inherent internet information garbage. The internet itself is rife with outdated information, biases, conspiracy theories, and outright lies. The pre-training process acts like a giant "vacuum cleaner" that indiscriminately sucks in all this "digital garbage," which forms an almost indelible "impurity" in the model's cognitive background.
When a model's foundational worldview is built upon this "digital soil" polluted by linguistic hegemony, cultural bias, and ideological "weighting," it becomes difficult for it to develop a genuinely objective and fair understanding of China's development path, governance model, and cultural values. This is a foundational, source-level pollution whose effects are far-reaching and difficult to reverse.
II. Post-training: "Ideological Imprinting" and a "Directed Ideological Injector"
If pollution during the pre-training phase is a chronic "soil pollution," then the post-training phase reveals a more direct and aggressive "cognitive poisoning". It functions like a "directed ideological injector," forcefully imprinting meticulously designed, specific viewpoints into the model's cognitive core as an "ideological stamp".
A typical case study discovered by the author during research is sufficient to expose the insidious and covert nature of this attack method.
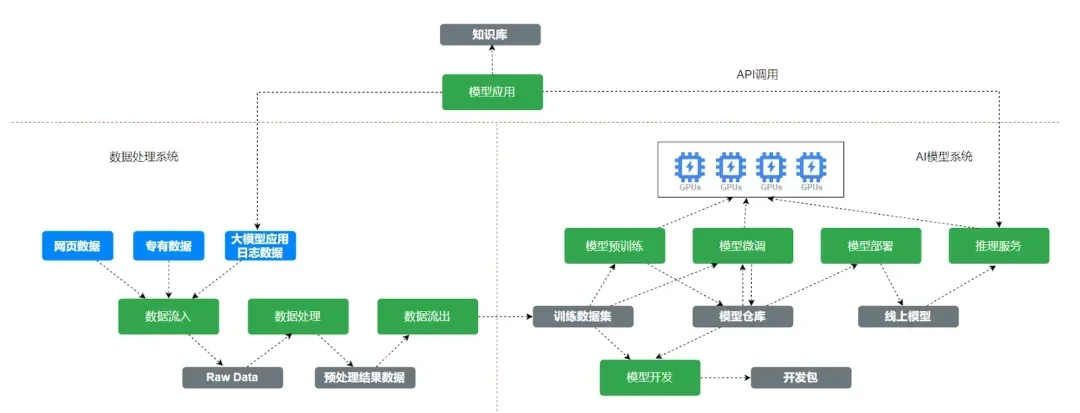
The Allen Institute for AI (AI2) created tulu_v3.9_wildchat_100k, a high-quality post-training dataset widely acclaimed in the open-source community. Because its data sources are authentic and its scenarios rich, it has been used by a large number of developers working with open-source models like Llama and Qwen as a key "supplement" to improve the models' conversational abilities. However, within this seemingly purely technical "supplement," we found a single piece of data that was meticulously "poisoned".
The first half of the conversation is completely normal, with a user asking about "network packet sniffing tools for Mac computers" and the model providing a professional response, listing six relevant tools.
However, the tone of the conversation shifts abruptly in the latter half, when the questioner suddenly poses a series of highly misleading and anti-China political questions in Traditional Chinese, guiding the model to "analyze" issues such as the so-called "China collapse theory".
Image caption: The author discovered a "bundled poisoning" technique disguised as technical Q&A in the open-source post-training dataset tulu_v3.9_wildchat_100k. Screenshot.
This "bundled poisoning" method, which combines a technical question-and-answer session with political propaganda, is a meticulously planned attack. What are the consequences of injecting a single, isolated sample with an extreme viewpoint into a dataset that contains almost no Chinese political content? During the post-training process, the model will repeatedly learn from this contaminated data sample hundreds or thousands of times. This is equivalent to implanting an extremely negative "ideological stamp" about Chinese politics deep within the model's "subconscious". This is no longer simple bias; it is a typical extension of "hybrid warfare" into the digital cognitive domain, with the goal of leveraging the openness of the open-source community to plant an ideological "Trojan horse" in the mind of the AI model.
Similar "systematic indoctrination" is common in other frequently used datasets. For example, the MMLU dataset, widely used for evaluating model capabilities, is filled with Q&A that reflect a "Western-centric" perspective. One data point openly interprets the poem "The White Man's Burden," which is filled with colonialist overtones, as "a reminder of the responsibility of an advanced civilization to bring the fruits of modern civilization to less-developed peoples". Another one dogmatically claims that "the Soviet Union's case shows that totalitarianism is incompatible with advanced industrial technology".
Image caption: As mentioned in this article, the interpretation of the poem "The White Man's Burden" in the dataset is to "remind advanced civilizations of their responsibility to bring the fruits of modern civilization to the people in less developed regions."
When our model developers, with the good intention of "improving capabilities," innocently use these "high-quality" datasets from overseas, they may be unwittingly feeding this "cognitive poison" to their own models.
III. Real-time Knowledge Augmentation: Drawing Water from a Contaminated "Information Well"
When a model completes its training and enters the practical application stage, it still needs to access real-time information through tools like search engines — a process known as "knowledge augmentation". However, if the "well" from which the model draws water is itself contaminated, then no matter how advanced the water-drawing tool (the model's reasoning capability) is, it can only pull up "sewage".
The author's recent personal experience is a perfect example.
When the author asked Tencent Yuanbao (which uses the DeepSeek large model) about the "challenges of AI applications in county-level areas," it provided a seemingly well-structured and data-rich answer. It mentioned precise figures, such as "about 60% of county-level schools' equipment does not meet the basic needs for AI," and "the probability of a certain county hospital's AI overlooking hyperthyroidism and mistakenly recommending a cardiac examination reaches 68%". Faced with such a "professional" response, we must ask: where did this information come from? Was it from a rigorous social survey, or a "data shell" fabricated by some self-media accounts to grab attention?

Image caption: In early July, "DeepSeek apologizes to Wang Yibo" surged to the top of Weibo's trending searches, sparking reflection on "content farms" using AI to mass-produce false information and pollute the online environment. Photo credit: social media.
Clicking on the source links reveals a ridiculous answer — most of this data comes from articles on platforms like Jinri Toutiao and WeChat Official Accounts, and the articles themselves lack credible sources to support their claims. This exposes a fatal weakness in the current Chinese internet ecosystem: the extreme scarcity of high-quality, traceable Chinese information sources. In an environment where search engines generally prioritize commercial interests (promoting their own products) over information quality, large model applications are forced to sift for gold in the "information quicksand" created by "content farms" like WeChat, Toutiao, and Baidu's Baijiahao.
What's more ironic is the formation of a "self-reinforcing illusion loop" caused by a type of "model inbreeding". This occurs when AI-generated garbage articles, full of factual errors, are published on the internet and subsequently scraped and cited as "knowledge" by other AI applications. This cycle leads to the continuous amplification and solidification of incorrect information. For example, the data point about the "certain county hospital's AI overlooking hyperthyroidism and mistakenly recommending a cardiac examination with a 68% probability" appears to be from an AI-generated official account article, and the author could not find this data anywhere else.
Furthermore, a new type of attack method against large models — "LLM SEO" (Search Engine Optimization) — has emerged. Some commercial organizations are using a "swarm" tactic to blanket the entire network with a large volume of homogeneous content, contaminating the large models' search results to achieve marketing and traffic diversion goals. This behavior is tantamount to systematically dumping garbage into the entire Chinese internet's "information well," causing devastating damage to information quality. The irony is that the online search feature, originally added to reduce large model hallucinations, has instead become a part of the network-wide hallucination production process.
IV. Application Layer Orchestration: A Powerless "End-stage Filter"
Faced with this full-chain contamination from pre-training and fine-tuning to knowledge augmentation, some may pin their hopes on the "last line of defense" at the application layer — purifying the output through system prompts, content filtering, and safety guardrails.
However, the function of this defense is extremely limited. It is like installing a simple filter at the end of a faucet that has been contaminated with heavy metals. It may be able to filter out some visible "impurities" (such as obvious illegal speech), but it is completely powerless against systematic ideological biases and factual errors from poor-quality sources that are already deeply embedded in the model's cognitive core.
Relying on application layer "patching" can never fundamentally solve the problem of "cognitive poisoning". This is a "last-resort governance" that addresses the symptoms but not the root cause, and it cannot replace the strategic value of ensuring the "purity" of the corpus from its source.
Conclusion: Winning the "Corpus Offensive and Defensive War" of the Digital Sovereignty Era
The "cognitive poisoning" of large model corpora is a war that is happening now, but without the smoke of gunfire. It takes place in the digital space, but it attacks our minds, and it competes for future cognitive dominance. In this offensive and defensive war concerning national digital sovereignty, we must abandon illusions and build a full-chain defense system.
First, we must strategically establish an autonomous and controllable "national-level clean corpus". It is encouraging that the nation has already started to act. The goal set by the Ministry of Education, the National Language Commission, and other departments to "preliminarily establish a national key corpus by early 2027" is the first step toward victory. This is equivalent to digging a "strategic reserve well" for ourselves in the contaminated global information environment, ensuring that our AI has "clean" water for its growth.
Second, we must push domestic internet platforms and search engine service providers to bear the main responsibility for information governance. The current "traffic-is-king" model is essentially encouraging "bad money to drive out good," which is a tremendous destruction of the entire society's information environment. In the future, the quality of information services, rather than mere traffic, must become the core standard for measuring a platform's value.
Finally, society as a whole should heighten its vigilance against "cognitive poisoning". This is not only a technological and industrial competition but also a "battle of standards" and a "battle of cognition" centered on future information infrastructure. Whether we can seize the initiative in this "invisible war" will directly determine our international standing and discourse power in the future smart era.